- is open source
- is a large ecosystem: Hue, Solr, Flume
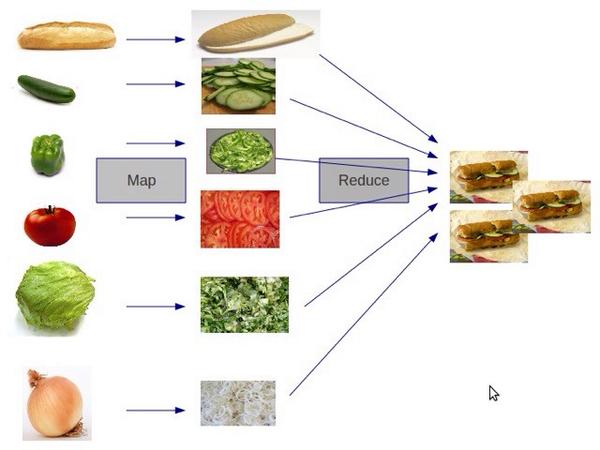
MapReduce:
- the mapper

- shuffle and sort
- reduce
Cluster - is a group of machine working together

Когда мы говорим про Hadoop, то в первую очередь имеем в виду его файловую систему — HDFS (Hadoop Distributed File System). Самый простой способ думать про HDFS — это представить обычную файловую систему, только больше. Обычная ФС, по большому счёту, состоит из таблицы файловых дескрипторов и области данных. В HDFS вместо таблицы используется специальный сервер — сервер имён (NameNode), а данные разбросаны по серверам данных (DataNode).

HDFS — глобальная файловая система, распределенная через кластер, которая обеспечивает хранение данных. Файлы разбиваются на большие блоки, как правило, 64, 128 или 512 Мб, после чего они записываются на разные узлы кластера. Таким образом, на HDFS могут быть размещены файлы любого размера, даже превышающие объем хранилища одного сервера. Каждый записанный блок еще минимум дважды реплицируется на другие узлы. С одной стороны, репликация обеспечивает отказоустойчивость. С другой — возможность локальной обработки данных без нагрузки на сетевую инфраструктуру. Объем дискового пространства кластера при стандартном коэффициенте репликации должен быть в три раза больше, чем информация, которую требуется сохранить. Также необходимо иметь дополнительно 25–30% вне HDFS для хранения промежуточных данных, возникающих в процессе обработки. То есть на 1 Тб «полезной информации» нужно 4 Тб «сырого пространства».
DFS: архитектура
Есть кластер из машин, которых много, на которых хранятся данные. Есть одна машина, которая называется master node, и которая координирует все.
Что хранится на мастер-ноде? На мастер-ноде просто хранится таблица файлов. Структура файловой системы, каждый файл разбит на блоки, на каких конкретно кластерных машинах, храниться какие блоки файлов.
Как происходит запись и чтение? Мы хотим прочитать какой-то файл, мы спрашиваем у мастер-ноды где хранятся блоки такого-то файла, он нам говорит, на какой машине хранятся конкретные блоки, и мы уже читаем напрямую из кластерных машин.
То же самое с записью, мы спрашиваем у мастер-ноды, куда нужно писать, в какие конкретно блоки, в какие конкретно машины, он нам говорит, и мы записываем напрямую туда.
А для обеспечения надежности, каждый блок хранится в нескольких экземплярах, на нескольких машинах. Этим обеспечивается надежность, даже если у нас выйдет из строя, скажем, 10% машин в кластере, скорее всего, мы ничего не потеряем. Т.е. да, мы потеряем какие-то блоки, но поскольку эти блоки хранятся в нескольких экземплярах, мы сможем опять таки и читать и записывать
MapReduce
Первая операция…, у нас есть какие-то входные данные, например, набор каких-нибудь input record-ов.
Первая операция, которая называется Map, которая по каждому input record-у выдает нам пару «ключ → значение». После этого, внутри, эти пары «ключ → значение» группируются, каждому ключу, когда мы обработаем все входные записи может соответствовать несколько значений. Группируются, и выдаются на процедуру Reduce, которая получает ключ, и соответственно, набор значений, и выдает уже, окончательно финальный результат.
Таким образом, у нас уже есть набор каких-то input record-ов, например, это строчки в лог-файле, и мы получаем какой-то набор output record-ов.
Выглядит все это достаточно странно, как какая-то узкоспециализированная вещь, как что-то из функционального программирования, непонятно сразу, как это может применяться на широкой практике.
Пример
На самом деле, очень хорошо может применяться на широкой практике.Самый простой пример. Пусть мы компания Facebook, у нас очень много данных,… ну просто логи показываем страниц на фейсбуке. И надо посчитать, каким броузером кто пользуется.
Это сделать, с помощью парадигмы MapReduce довольно легко.
Мы определяем операцию Map, которая по строчке в access loge определяет ключ-значение, где ключ — это броузер, а значение — просто единичка.
После этого, остается сделать операцию Reduce, которая по набору броузеров и множеству единичек просто делает суммирование, и на выходе выдает для каждого броузера полученную сумму.
Мы запускаем эту задачу MapReduce на кластере, в начале у нас много-много лог файлов, в конце у нас такой маленький файлик, в котором у нас есть броузер, и соответственно, количество показов. Таким образом мы узнаем статистику.
Паралленьность
Почему это хорошо, MapReduce?Такие вот программы, когда мы задаем Map и задаем Reduce, они очень хорошо параллелятся.
Допустим у нас есть какой-то Input, это большой файл, или наборы файлов, этот файл можно разбить на много-много маленьких кусочков, например, по числу машин в кластере, или больше. Соответственно, на каждом кусочке мы запустим нашу функцию Map, это можно делать параллельно, все это запускается на кластере, по-тихонечку вычисляется, результат каждого map-а, внутри как-то сортируется, и отправляется на Reduce.
То же самое, когда у нас есть результат какого-то Map-а, много каких-то данных, мы можем опять эти данные разбить на кусочки, опять таки запустить на кластере, на многих машинах.
Благодаря этому и достигается масштабируемость. Когда нам нужно обрабатывать данные в два раза быстрее, мы просто добавим в два раза больше машин, железо сейчас относительно дешевое, т.е. без всякого изменения архитектуры мы получим в два раза большую производительность.
MapReduce — система для распределения задачи обработки данных между узлами Hadoop-кластера. Этот процесс, как ни странно, состоит из двух стадий: Map и Reduce. Map запускается одновременно на многих узлах и выдает промежуточную информацию, обрабатываемую Reduce для предоставления конечного результата.
Приведу упрощенный пример, который поможет лучше понять происходящее. Представьте, что вам необходимо посчитать число повторений слов в газете. Вы будете записывать каждое слово и ставить галочку напротив, когда оно снова встретится в тексте. Этот процесс займет очень много времени, особенно если вы собьетесь и придется начинать все заново. Гораздо проще будет разделить газету на небольшие части и раздать их друзьям и знакомым с просьбой выполнить подсчет. Таким образом, задача будет распределена и каждый предоставит вам некоторый промежуточный результат. Поскольку данные уже прошли предварительную сортировку, то ваша задача будет очень простой — просуммировать полученную информацию. Выражаясь терминами Hadoop, ваши друзья выполнят стадию Map, а вы — Reduce. К слову, промежуточные данные носят название Shuffle, а кусочки газеты — Chunk.
Наилучшим считается вариант, когда процесс Мap работает с информацией на локальном диске. Если такой возможности нет по причине высокой утилизации узла, то задача будет передана другой ноде, которая предварительно скопирует данные, чем увеличит нагрузку на сеть. Если бы на HDFS хранилась только одна копия информации, то случаи удаленной обработки были бы частыми. По умолчанию HDFS создает три копии данных на разных узлах, и это хороший коэффициент для обеспечения отказоустойчивости и локальных вычислений.
Существует два типа узлов: SlaveNodes и MasterNodes. Узлы SlaveNode непосредственно записывают и обрабатывают информацию, запускают демоны DataNode и TaskTracker. MasterNodes выступают управляющими, они хранят метаданные файловой системы и обеспечивают распределение блоков на HDFS (NameNode), а также координируют MapReduce с помощью демона Job Tracker. Каждый демон запускается на своей собственной Java Virtual Machine (JVM).
Рассмотрим процесс записи на HDFS файла, разбитого на два блока (Рисунок 2). Клиент обращается к NameNode(NN) с запросом, на какие DataNode (DN) эти блоки должны быть помещены. NameNode дает инструкцию поместить Block1 на DN1. Кроме того, NameNode командует DN1 выполнить репликацию Block1 на DN2, а DN2 — на DN6. Аналогичным образом Block2 помещается на узлы DN2, DN5 и DN6. Каждый DN с периодичностью в несколько секунд отправляет NN отчет об имеющихся блоках. Если отчет не приходит, то DN считается потерянным, а это означает, что на одну реплику определенных блоков стало меньше. NN инициирует их восстановление на других DN. Если через некоторое время пропавший DN появится вновь, то NN выберет DN, с которых будут удалены лишние копии данных.

Рисунок 2. Процесс записи на HDFS
Эквивалентен NameNode по важности демон JobTracker, управляющий распределенной обработкой данных. Если вы хотите запустить программу на всем кластере, то она отправляется MasterNode с демоном JobTracker. JobTracker определяет, какие блоки данных нужны, и выбирает узлы, где стадия Мap может быть выполнена локально; кроме того, выбираются узлы для Reduce. Со стороны SlaveNode процесс взаимодействия с JobTracker выполняется демоном TaskTracker. Он сообщает JobTracker статус выполнения задачи. Если задача не осуществлена по причине ошибки или слишком длительного времени исполнения, то JobTracker передаст ее другому узлу. Частое невыполнение задачи узлом ведет к тому, что он будет помещен в черный список.

Рисунок 3. Процесс обработки данных MapReduce
Таким образом, для сетевой инфраструктуры Hadoop-кластер производит несколько типов трафика:
— Heartbeats — служебная информация между MasterNodes и SlaveNodes, с помощью которой определяются доступность узлов, статус исполнения задач, отправляются команды на репликацию или удаление блоков и т. д. Нагрузка Heartbeats на сеть минимальна, и эти пакеты не должны теряться, так как от них зависит стабильность работы кластера.
— Shuffle — данные, которые передаются после выполнения стадии Мар на Reduce. Природа трафика — от многих к одному, генерирует среднюю нагрузку на сеть.
— Запись на HDFS — запись и репликация больших объемов данных большими блоками. Высокая нагрузка на сеть.
Apache Hadoop
Apache Hadoop — что это такое? После того, как Гугл опубликовал эти статьи, все решили, что это очень удобная парадигма, в частности, возник проект Apache Hadoop. Они просто решили, что то, что написано в этих статьях, про distributed file systems и парадигму MapReduce, реализовать, как open-source проект на Java.Движки: MapReduce, Spark, Tez
При правильной архитектуре приложения, информация о том, на каких машинах расположены блоки данных, позволяет запустить на них же вычислительные процессы (которые мы будем нежно называть англицизмом «воркеры») и выполнить большую часть вычислений локально, т.е. без передачи данных по сети. Именно эта идея лежит в основе парадигмы MapReduce и её конкретной реализации в Hadoop.
Классическая конфигурация кластера Hadoop состоит из одного сервера имён, одного мастера MapReduce (т.н. JobTracker) и набора рабочих машин, на каждой из которых одновременно крутится сервер данных (DataNode) и воркер (TaskTracker). Каждая MapReduce работа состоит из двух фаз:
- map — выполняется параллельно и (по возможности) локально над каждым блоком данных. Вместо того, чтобы доставлять терабайты данных к программе, небольшая, определённая пользователем программа копируется на сервера с данными и делает с ними всё, что не требует перемешивания и перемещения данных (shuffle).
- reduce — дополняет map агрегирующими операциями
На самом деле между этими фазами есть ещё фаза combine, которая делает то же самое, что и reduce, но над локальными блоками данных. Например, представим, что у нас есть 5 терабайт логов почтового сервера, которые нужно разобрать и извлечь сообщения об ошибках. Строки независимы друг от друга, поэтому их разбор можно переложить на задачу map. Дальше с помощью combine можно отфильтровать строки с сообщением об ошибке на уровне одного сервера, а затем с помощью reduce сделать то же самое на уровне всех данных. Всё, что можно было распараллелить, мы распараллелили, и кроме того минимизировали передачу данных между серверами. И даже если какая-то задача по какой-то причине упадёт, Hadoop автоматически перезапустит её, подняв с диска промежуточные результаты. Круто!
Проблема в том, что большинство реальных задач гораздо сложней одной работы MapReduce. В большинстве случаев мы хотим делать параллельные операции, затем последовательные, затем снова параллельные, затем комбинировать несколько источников данных и снова делать параллельные и последовательные операции. Стандартный MapReduce спроектирован так, что все результаты — как конечные, так и промежуточные — записываются на диск. В итоге время считывания и записи на диск, помноженное на количество раз, которые оно делается при решении задачи, зачастую в несколько (да что там в несколько, до 100 раз!) превышает время самих вычислений.
И здесь появляется Spark. Спроектированный ребятами из университета Berkeley, Spark использует идею локальности данных, однако выносит большинство вычислений в память вместо диска.
SQL: Hive, Impala, Shark, Spark SQL, Drill
Несмотря на то, что Hadoop является полноценной платформой для разработки любых приложений, чаще всего он используется в контексте хранения данных и конкретно SQL решений. Собственно, в этом нет ничего удивительного: большие объёмы данных почти всегда означают аналитику, а аналитику гораздо проще делать над табличными данными. К тому же, для SQL баз данных гораздо проще найти и инструменты, и людей, чем для NoSQL решений. В инфраструктуре Hadoop-а есть несколько SQL-ориентированных инструментов:Hive — самая первая и до сих пор одна из самых популярных СУБД на этой платформе. В качестве языка запросов использует HiveQL — урезанный диалект SQL, который, тем не менее, позволяет выполнять довольно сложные запросы над данными, хранимыми в HDFS. Здесь надо провести чёткую линию между версиями Hive <= 0.12 и текущей версией 0.13: как я уже говорил, в последней версии Hive переключился с классического MapReduce на новый движок Tez, многократно ускорив его и сделав пригодным для интерактивной аналитики. Т.е. теперь вам не надо ждать 2 минуты, чтобы посчитать количество записей в одной небольшой партиции или 40 минут, чтобы сгруппировать данные по дням за неделю (прощайте длительные перекуры!). Кроме того, как Hortonworks, так и Cloudera предоставляют ODBC-драйвера, позволяя подключить к Hive такие инструменты как Tableau, Micro Strategy и даже (господи, упаси) Microsoft Excel.
Impala — продукт компании Cloudera и основной конкурент Hive. В отличие от последнего, Impala никогда не использовала классический MapReduce, а изначально исполняла запросы на своём собственном движке (написанном, кстати, на нестандартном для Hadoop-а C++). Кроме того, в последнее время Impala активно использует кеширование часто используемых блоков данных и колоночные форматы хранения, что очень хорошо сказывается на производительности аналитических запросов. Так же, как и для Hive, Cloudera предлагает к своему детищу вполне эффективный ODBC-драйвер.
Hive, Pig and Impala are used for data analysis
NoSQL: HBase
Несмотря на популярность SQL решений для аналитики на базе Hadoop, иногда всё-таки приходится бороться с другими проблемами, для которых лучше приспособлены NoSQL базы. Кроме того, и Hive, и Impala лучше работают с большими пачками данных, а чтение и запись отдельных строк почти всегда означает большине накладные расходы (вспомним про размер блока данных в 64Мб).И здесь на помощь приходит HBase. HBase — это распределённая версионированная нереляционная СУБД, эффективно поддерживающая случайное чтение и запись. Здесь можно рассказать про то, что таблицы в HBase трёхмерные (строковый ключ, штамп времени и квалифицированное имя колонки), что ключи хранятся отсортированными в лексиграфическом порядке и многое другое, но главное — это то, что HBase позволяет работать с отдельными записями в реальном времени. И это важное дополнение к инфраструктуре Hadoop. Представьте, например, что нужно хранить информацию о пользователях: их профили и журнал всех действий. Журнал действий — это классический пример аналитических данных: действия, т.е. по сути, события, записываются один раз и больше никогда не изменяются. Действия анализируются пачками и с некоторой периодичностью, например, раз в сутки. А вот профили — это совсем другое дело. Профили нужно постоянно обновлять, причём в реальном времени. Поэтому для журнала событий мы используем Hive/Impala, а для профилей — HBase.
При всём при этом HBase обеспечивает надёжное хранение за счёт базирования на HDFS. Стоп, но разве мы только что не сказали, что операции случайного доступа не эффективны на этой файловой системе из-за большого размера блока данных? Всё верно, и в этом большая хитрость HBase. На самом деле новые записи сначала добавляются в отсортированную структуру в памяти, и только при достижении этой структурой определённого размера сбрасываются на диск. Консистентность при этом поддерживается за счёт write-ahead-log (WAL), который пишется сразу на диск, но, естественно, не требует поддержки отсортированных ключей.
Запросы к таблицам HBase можно делать напрямую из Hive и Impala.
Импорт данных: Kafka
Обычно импорт данных в Hadoop проходит несколько стадий эволюции. Вначале команда решает, что обычных текстовых файлов будет достаточно. Все умеют писать и читать CSV файлы, никаких проблем быть не должно! Затем откуда-то появляются непечатные и нестандартные символы (какой мерзавец их вставил!), проблема экранирования строк и пр., и приходится перейти на бинарные форматы или как минимум переизбыточный JSON. Затем появляется два десятка клиентов (внешних или внутренних), и не всем удобно посылать файлы на HDFS.Apache Kafka — распределённую систему обмена сообщениями с высокой пропускной способностью. В отличие от интерфейса HDFS, Kafka предоставляет простой и привычный интерфейс передачи сообщений.
Kafka остаётся единственным проектом, на уровне архитектуры решающим вопрос импорта большого объёма данных.
Потоковая обработка
Картинка выше прекрасно выражает состояние многих компаний: все знают, что большие данные — это хорошо, но мало кто реально понимает, что с ними делать. А делать с ними нужно в первую очередь две вещи — переводит в знания (читать как: использовать при принятии решений) и улучшать алгоритмы. С первым уже помогают инструменты аналитики, а второе сводится к машинному обучению. В Hadoop для этого есть два крупных проекта:Mahout — первая большая библиотека, реализовавшая многие популярные алгоритмы средствами MapReduce. Включает в себя алгоритмы для кластеризации, коллаборативной фильтрации, случайных деревьев, а также несколько примитивов для факторизации матриц. В начале этого года организаторы приняли решение перевести всё на вычислительное ядро Apache Spark, которое гораздо лучше поддерживает итеративные алгоритмы (попробуйте прогнать 30 итераций градиентного спуска через диск при стандартном MapReduce!).
MLlib. В отличие от Mahout, который пытается перенести свои алгоритмы на новое ядро, MLlib изначально является подпроектом Spark. В составе: базовая статистика, линейная и логистическая регрессия, SVM, k-means, SVD и PCA, а также такие примитивы оптимизации как SGD и L-BFGS. Scala интерфейс использует для линейной алгебры Breeze, Python интерфейс — NumPy. Проект активно развивается и с каждым релизом значительно прибавляет в функционале.
Форматы данных: Parquet, ORC, Thrift, Avro
Если вы решите использовать Hadoop по полной, то не помешает ознакомиться и с основными форматами хранения и передачи данных.
Parquet — колончатый формат, оптимизированный для хранения сложных структур и эффективного сжатия. Изначально был разработан в Twitter, а сейчас является одним из основных форматов в инфраструктуре Hadoop (в частности, его активно поддерживают Spark и Impala).
ORC — новый оптимизированный формат хранения данных для Hive. Здесь мы снова видим противостояние Cloudera c Impala и Parquet и Hortonworks с Hive и ORC. Интересней всего читать сравнение производительности решений: в блоге Cloudera всегда побеждает Impala, причём со значительным перевесом, а в блоге Hortonworks, как несложно догадаться, побеждает Hive, причём с не меньшим перевесом.
Thrift — эффективный, но не очень удобный бинарный формат передачи данных. Работа с этим форматом предполагает определение схемы данных и генерацию соответсвующего кода клинета на нужном языке, что не всегда возможно. В последнее время от него стали отказываться, но многие сервисы всё ещё используют его.
Avro — в основном позиционируется как замена Thrift: он не требует генерации кода, может передавать схему вместе с данными или вообще работать с динамически типизированными объектами.
Прочее: ZooKeeper, Hue, Flume, Sqoop, Oozie, Azkaba
Ну и напоследок коротко о других полезных и бесполезных проектах.
ZooKeeper — главный инструмент координации для всех элементов инфраструктуры Hadoop. Чаще всего используется как сервис конфигурации, хотя его возможности гораздо шире. Простой, удобный, надёжный.
Hue — веб-интерфейс к сервисам Hadoop, часть Cloudera Manager. Работает плохо, с ошибками и по настроению. Пригоден для показа нетехническим специалистам, но для серьёзной работы лучше использовать консольные аналоги.
Flume — сервис для организации потоков данных. Например, можно настроить его для получения сообщений из syslog, агрегации и автоматического сбрасывания в директорию на HDFS. К сожалению, требует очень много ручной конфигурации потоков и постоянного расширения собственными Java классами.


Oozie — планировщик потоков задач. Изначально спроектирован для объединения отдельных MapReduce работ в единый конвеер и запуска их по расписанию. Дополнительно может выполнять Hive, Java и консольные действия, но в контексте Spark, Impala и др., этот список выглядит довольно бесполезным. Очень хрупкий, запутанный и практически не поддаётся отладке.
Azkaban — вполне годная замена Oozie. Является частью Hadoop-инфраструктуры компании LinkedIn. Поддерживает несколько типов действий, главное из которых — консольная команда (а что ещё надо), запуск по расписанию, логи приложений, оповещения об упавших работах и др. Из минусов — некоторая сыроватость и не всегда понятный интерфейс (попробуйте догадаться, что работу нужно не создавать через UI, а заливать в виде zip-архива с текстовыми файлами).
Взято тут
тут
тут
Немає коментарів:
Дописати коментар